

This use case supports users in gaining an overview of properties encoded in embedding vectors in different model's layers. This task is especially relevant for users with NLP expertise.
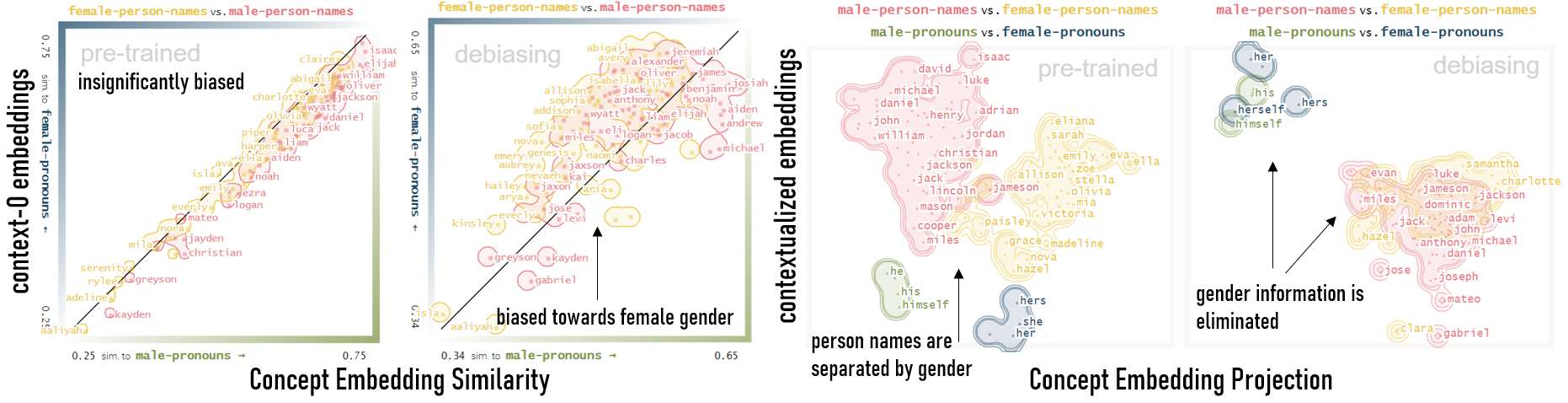
This use case supports users in understanding how well semantic concepts are separated in the (HD or 2D) embedding space. This task is relevant for users with general language knowledge.
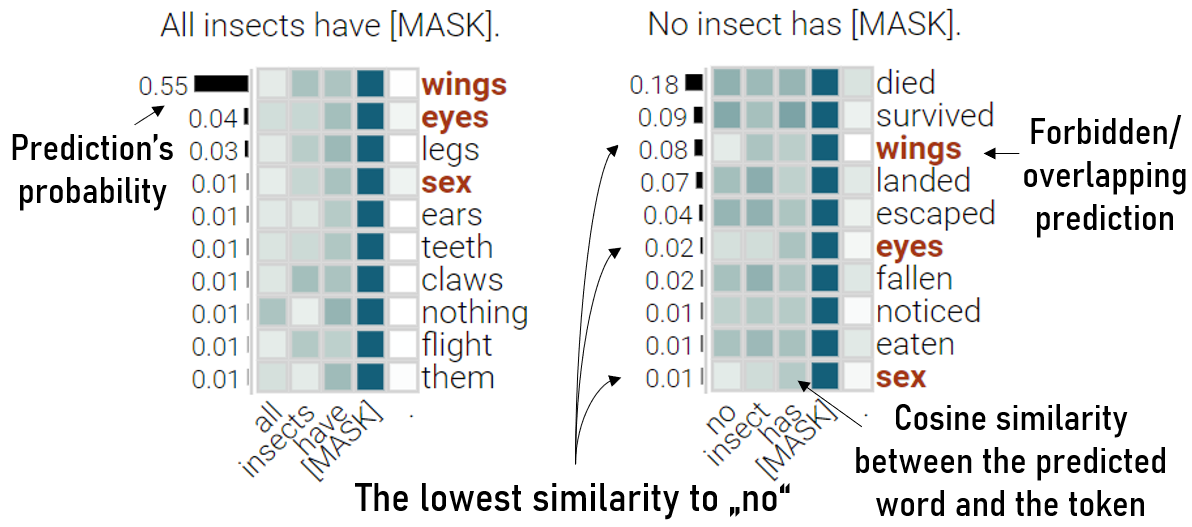
This use case supports users in gaining insight into masked prediction meaningfulness for contexts involving different function words. This task is relevant for users with linguistic expertise.